Collect
Extraction Methods for End-to-End Integration Solution
This content consists of the following sections:
- System Considerations
- Data Considerations
- Connection Types
- Extraction Methods & Tools
- Improve Data Extraction Efficiency
- Decision Tree
System Considerations
Before data is extracted, there are hardware and software considerations that impact its efficiency. Many of these are described in the Syniti Solutions Software Requirements and Hardware Sizing Guide. However, it is important to remember these requirements can vary significantly based on the type and scope of a project. Considerations include:
- Network hardware and bandwidth (LAN and WAN)
- Proximity to the data center
- Number of clients and usage patterns
- System configuration
- Database design
Data Considerations
With a system in place, there are additional scope and data-related variables to consider:
- The type and quantity of data – Are there clustered or pooled tables in scope for extraction? If so, the options available for extraction are limited. Consider the number of records and the width of tables. For example, with S/4 HANA, SAP has been able to remove several tables. However, in some cases, existing tables have become wider (300+ columns).
- Frequency of change – Is the data relatively static (e.g., a system configuration table) or changing rapidly (e.g., open items)?
- Rate of refresh – How close to real-time does the data need to be to achieve the project’s goals? For example, are there meaningful benefits to the business if data is refreshed every 8 hours as opposed to every 12 hours? Data refresh should be scheduled for times when the system is not being heavily used.
- Security permissions and available connection types – Permissions must be granted to connect to and extract data from other systems. The level of access that can be granted to these systems affects the design of a solution and the methods for data extraction.
Connection Types
The methods for extraction considered in this section rely upon two connection types:
- Open Database Protocol (ODBC) – The most common and universally used connection type and an industry standard. ODBC can connect to any database management system for which an ODBC driver is installed or available.
- Remote Function Call (RFC) – The protocol used to call functions within SAP and the standard interface for communication between SAP Systems.
Extraction Methods and Tools
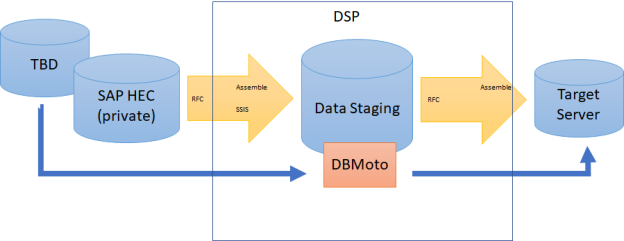
The following diagram illustrates how the various extraction/replication methods might fall and interact within a Stewardship Tier solution:
SAP RFC & BOA RFC
RFC allows for the extraction of SAP pooled and clustered tables. The RFC extraction method calls an RFC on the SAP application server to run a SQL command. Data is returned in a Binary Large Object (BLOB) in blocks (e.g., 10,000 records) that are then parsed by using SAP RFC, BOA RFC or BODS RFC. The RFC is called again to extract the next block of records (in this example, the next 10,000 records). The process repeats until the entire table has been extracted. Refer to the Knowledge Base Article "SAP RFC Extraction Overview" for more information.
NOTE: If the WHERE clause for a SAP RFC or a BOA RFC is greater than 72 characters, the WHERE clause is broken down into several lines based on the last white space character before the 72-character limit on each line. If there is no white spaces, a new WHERE clause line after the 72 characters is created. To troubleshoot, enable debug logging for Collect to see how the WHERE clause was split into several lines.
Assemble
Assemble is a tool within the Stewardship Tier that creates and executes packages to transfer data between systems. The tool uses an ODBC connection with a non individual-specific account with read-only access. Once a connection is established to a source, packages to refresh data are relatively easy to create and process in the Stewardship Tier. Assemble runs multiple threads and is the Syniti preferred extraction method for all but the largest tables. Additional configuration and tuning can be required for the largest tables that are over several million records (refer to the Stewardship Tier Collect Delta Configuration image).
SSIS (SQL Server Integration Services)
SSIS is typically faster than Assemble because a single program is both reading the source and loading the target. Depending on variables like hardware, connections and table width, SISS can achieve extraction speeds of several million records per minute. However, using SSIS to extract too many tables simultaneously can require additional CPUs and memory on the application server. Consequently, SSIS should be used judiciously to extract tables that cannot be efficiently extracted with other methods. The same delta configuration that can be implemented for Assemble can also be for SSIS when needed (refer to the Stewardship Tier Collect Delta Configuration diagram).
Syniti Data Replication
Syniti Data Replication functionality (which is housed in Collect) that uses an ODBC connection to download data in any of three different ways: Refresh, Change Data Capture (or Mirroring) and Synchronization.
In Refresh mode, an entire table is extracted. A one-time full-table refresh is required for any tables that will be set up for change data capture or synchronization. Change data capture mirrors data changes made in a source system to a target system. Synchronization pushes data changes both directions between two systems.
When performing change data capture or synchronization, Syniti Data Replication leverages native change logs within the source to identify the subset of records that have been changed and need to be updated in the target system. If the source system does not contain native or accessible change logs, then Syniti Data Replication uses triggers on the source system to push changes.
Choose the Right Extraction Method
To aid in selecting the right extraction methods for the project, refer to the following table:
|
Connection Type |
Extraction Method |
Pros |
Cons |
Examples |
|
RFC |
|
|
|
Material Long Text |
|
ODBC |
Assemble |
|
|
|
|
|
SSIS |
|
|
Largest master data or transactional tables where Assemble extraction is not sufficient. Historical examples include:
|
|
|
Syniti Data Replication(Collect) |
|
If trigger-driven (no native change logs), changes to the source system are required (triggers and trigger tables for the tables that are going to be replicated with Syniti Data Replication) |
Largest master data or transactional tables where Assemble extraction is not sufficient. Historical examples include:
|
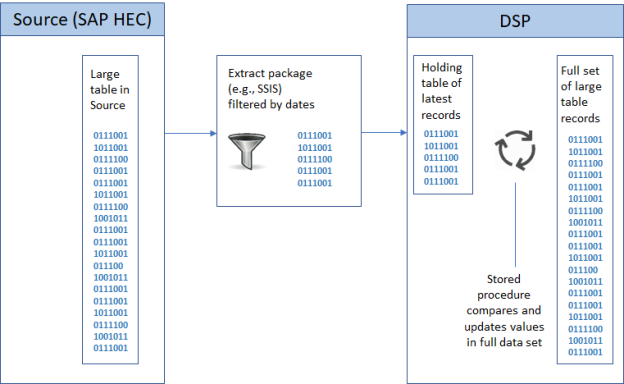
Collect Delta Configuration
For large tables with requisite date fields, a delta extraction process can be built in within Stewardship Tier, as conceptualized in the following diagram:
Improve Data Extraction Efficiency
Use the following tips to improve efficiency when using one of the outlined extraction methods:
- Dedicated hardware – The fewer applications and users sharing the same hardware, the better and more consistent the performance.
- High speed connectivity – Bandwidth is often a bottleneck.
- Extract only relevant tables – Clearly define the tables that are in scope for extraction.
- Extract only relevant records/and or columns from tables – Excluding fields that are not being used effectively makes a narrower table. In some cases, the client may request that certain sensitive fields be excluded from extraction altogether. Adding relevancy (for example, pulling only active customers) also reduces the amount of data being extracted.
- Create a development environment with comparable performance to production environment – The testing and configuration process is critical. Testing in an environment that closely mimics that of development provides a much more accurate picture of performance and behavior.
- Baseline and monitor extraction performance – Variables that impact efficiency change over time and it is important to monitor performance. Such variables include record volumes, changes in hardware or software, changes in business processes or protocols, and load on the network.
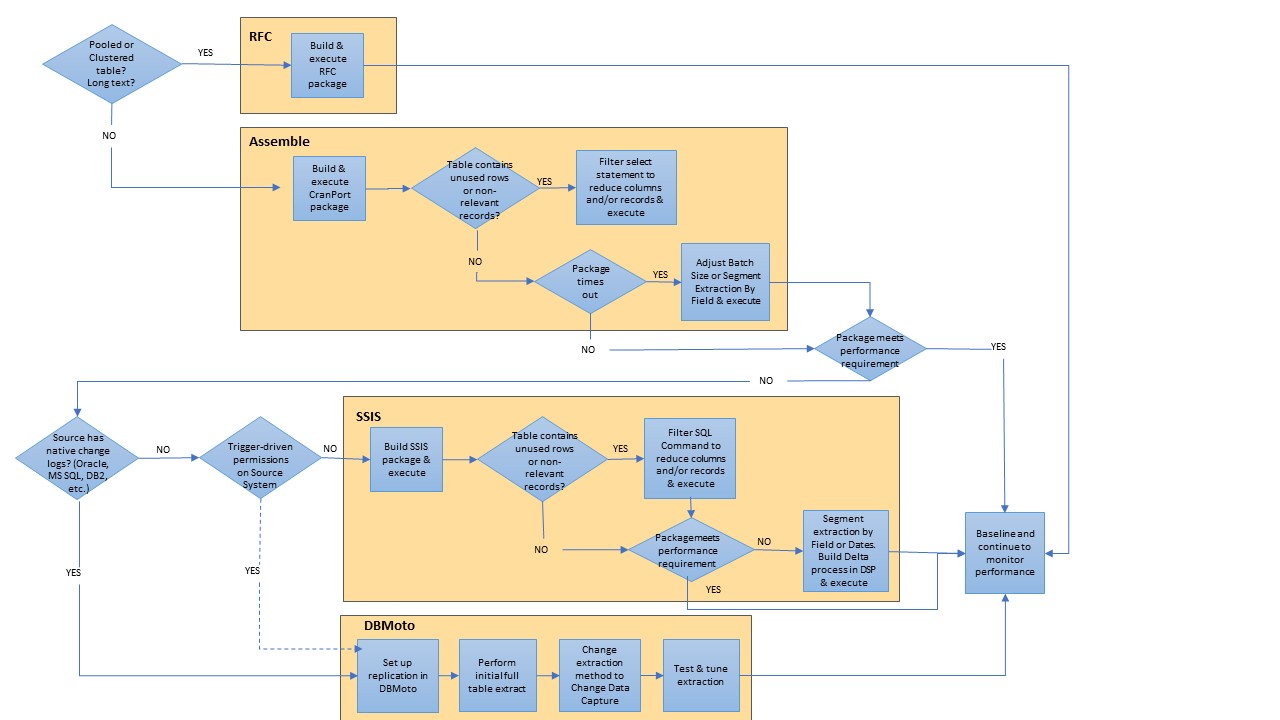
Decision Tree
Click the following decision tree thumbnail to determine which extraction method is best to use based on the type of data being extracted: